Lots of bugs have been fixed after the last prereleases, so here are
new ones:
http://gmerlin.sourceforge.net/gmerlin-dependencies-20101209.tar.bz2
http://gmerlin.sourceforge.net/gmerlin-all-in-one-20101209.tar.bz2
The good news is, that no new features were added so the code can stabilize better.
Please test this and report any problems.
The final gmerlin release is expected by the end of the year
Thursday, December 9, 2010
Saturday, September 18, 2010
gmerlin prereleases
Some time has gone since the last prereleases, and a lot of bugs have been
fixed since then. So here is another round:
http://gmerlin.sourceforge.net/gmerlin-dependencies-20100918.tar.bz2
http://gmerlin.sourceforge.net/gmerlin-all-in-one-20100918.tar.bz2
fixed since then. So here is another round:
http://gmerlin.sourceforge.net/gmerlin-dependencies-20100918.tar.bz2
http://gmerlin.sourceforge.net/gmerlin-all-in-one-20100918.tar.bz2
Saturday, August 7, 2010
Gmerlin configuration improvements
Up to now, gmerlins configuration philosophy was simple: Export all user settable parameters as possible to the frontends, no matter now important they are. There are 2 reasons for that:
A little look behind the GUI
A configuration dialog can contain of multiple nested sections. If you have more than one section, you see a tree structure on the right, which lets you select the section. A section contains all the configuration widgets you can see at the same time. Therefore the code must always distinguish if an action is for a section or for the whole dialog.
Factory defaults
Most configuration sections now have a button Restore factory defaults. It does, what the name suggests. You can use this if you think you messed something up.
Presets
Some configuration sections support presets. You can save all parameters into a file and load them again after. In some situations, presets are per section. In this case you see the preset menu below the parameter widgets. If the presets are global for the whole dialog window, you see the menu below the tree view. The next image shows a single-section dialog with the preset menu next to the restore button.

The next image shows a dialog with multiple sections. The preset menu is for the whole dialog, the restore button is for the section only.

The presets are designed such, that multiple applications can share them. E.g. an encoding setup configured in the transcoder can be reused in the recorder etc. Presets are available for:
- As a developer, I don't like to decide which configuration options are important.
- As a user I (personally) want to have full control over all program-and plugin settings. Nothing annoys me more in other applications than features, which could easily achieved by the backend, but they are not supported in the frontend.
A little look behind the GUI
A configuration dialog can contain of multiple nested sections. If you have more than one section, you see a tree structure on the right, which lets you select the section. A section contains all the configuration widgets you can see at the same time. Therefore the code must always distinguish if an action is for a section or for the whole dialog.
Factory defaults
Most configuration sections now have a button Restore factory defaults. It does, what the name suggests. You can use this if you think you messed something up.
Presets
Some configuration sections support presets. You can save all parameters into a file and load them again after. In some situations, presets are per section. In this case you see the preset menu below the parameter widgets. If the presets are global for the whole dialog window, you see the menu below the tree view. The next image shows a single-section dialog with the preset menu next to the restore button.

The next image shows a dialog with multiple sections. The preset menu is for the whole dialog, the restore button is for the section only.

The presets are designed such, that multiple applications can share them. E.g. an encoding setup configured in the transcoder can be reused in the recorder etc. Presets are available for:
- All plugins (always global for the whole plugin)
- Whole encoding setups
- Filter chains
Tuesday, August 3, 2010
Gmerlin prereleases
gmerlin prereleases can be downloaded here:
http://gmerlin.sourceforge.net/gmerlin-dependencies-20100803.tar.bz2
http://gmerlin.sourceforge.net/gmerlin-all-in-one-20100803.tar.bz2
Highlights of this development iteration:
http://gmerlin.sourceforge.net/gmerlin-dependencies-20100803.tar.bz2
http://gmerlin.sourceforge.net/gmerlin-all-in-one-20100803.tar.bz2
Highlights of this development iteration:
- Pass-through of compressed streams in the transcoder
- Native matroska demuxer with sample accurate seeking in webm files
- VP8 decoding via ffmpeg
- Lots of work on precise timing and sample accurate seeking
- Presets in the GUI configuration (will blog later about that)
- The gmerlin package reaches version one-zero
Sunday, August 1, 2010
Getting serious with sample accuracy
gmerlin-avdecoder has a sample accurate seek API for some time now. What was missing was a test to prove that seeking happens really with sample accuracy.
Test tool
The strictest test if a decoder library can seek with sample accuracy is to seek to a position, decode a video frame or a bunch of audio samples. Compare these with the frame/samples you get if you decode the file from the beginning. Of course, the timestamps must also be identical. A tool, which does this, is in
Audio codec details
When seeking in video streams, you have keyframes, which tell you where decoding of a stream can be resumed after a seek. It's sometimes difficult to implement this, but at least you always know what to do.
The naive approach for audio streams is to assume, that all blocks (e.g. 1152 samples for mp3) can be decoded independently. Unfortunately, reality is a bit more cruel:
Bit reservoir
This is a mechanism, which allows to make pseudo VBR in a CBR stream. If a frame can be encoded with fewer bits than allocated for the frame, it can leave the remaining bits to a subsequent (probably more complex) frame. The downside of this trick is, that after a seek, the next frame might need bits from previous frames to be fully decoded.
Oberlapping transform
Most audio compression techniques work in the frequency-domain, so between the audio signal and the compression stage, there is some kind of fft-like transform.
Now, for reasons beyond this post, overlapping transforms are used by some codecs. This means, that for decoding the first samples of a compressed block, you need the last samples of the previous block. The image below shows one channel of an AAC stream for the case that the overlapping was ignored when seeking. You see that the beginning of the frame is not reconstructed properly, because the previous frame is missing.

Both the bit reservoir and the overlapping can be boiled down to a single number, which tells how many sample before the actual seek point the decoder must restart decoding. This number is set by the codec during initialization, and it's used when we seek with sample accuracy.
Mysterious liba52 behavior
Even if sample accuracy was achieved, the AC3 streams (which are on DVDs or in AVCHD files) don't achieve bit exactness. The image below shows, that there is no time shift between the signals (which means that gmerlin-avdecoder seeks correctly), but the values are not exactly the same.

First I blamed the AC3 dynamic range control for this behavior. Dynamic range compressors always have some kind memory across several frames. But even after disabling DRC, the difference was still there. I would really be curious if that's a principal property of AC3 being non-deterministic or if it's a liba52 bug.
Conclusions
The table below lists all audio codecs, which were taken into consideration. They represent a huge percentage of all files found in the wild. The next important codecs are the uncompressed ones, but these are always sample accurate.
Obtaining the information summarized here was a very painful process with web researches and experiments. The documentation of the decoder libraries regarding sample accurate and bit exact seeking is extremely sparse if not non-existing.
Test tool
The strictest test if a decoder library can seek with sample accuracy is to seek to a position, decode a video frame or a bunch of audio samples. Compare these with the frame/samples you get if you decode the file from the beginning. Of course, the timestamps must also be identical. A tool, which does this, is in
tests/seektest.c. I noticed, that video streams easily pass this test, usually even if no sample accurate access was requested. That's probably because I thought, that video streams are more difficult. So I put more brainload into them. Therefore I'll concentrate on audio streams in this post.Audio codec details
When seeking in video streams, you have keyframes, which tell you where decoding of a stream can be resumed after a seek. It's sometimes difficult to implement this, but at least you always know what to do.
The naive approach for audio streams is to assume, that all blocks (e.g. 1152 samples for mp3) can be decoded independently. Unfortunately, reality is a bit more cruel:
Bit reservoir
This is a mechanism, which allows to make pseudo VBR in a CBR stream. If a frame can be encoded with fewer bits than allocated for the frame, it can leave the remaining bits to a subsequent (probably more complex) frame. The downside of this trick is, that after a seek, the next frame might need bits from previous frames to be fully decoded.
Oberlapping transform
Most audio compression techniques work in the frequency-domain, so between the audio signal and the compression stage, there is some kind of fft-like transform.
Now, for reasons beyond this post, overlapping transforms are used by some codecs. This means, that for decoding the first samples of a compressed block, you need the last samples of the previous block. The image below shows one channel of an AAC stream for the case that the overlapping was ignored when seeking. You see that the beginning of the frame is not reconstructed properly, because the previous frame is missing.

Both the bit reservoir and the overlapping can be boiled down to a single number, which tells how many sample before the actual seek point the decoder must restart decoding. This number is set by the codec during initialization, and it's used when we seek with sample accuracy.
Mysterious liba52 behavior
Even if sample accuracy was achieved, the AC3 streams (which are on DVDs or in AVCHD files) don't achieve bit exactness. The image below shows, that there is no time shift between the signals (which means that gmerlin-avdecoder seeks correctly), but the values are not exactly the same.

First I blamed the AC3 dynamic range control for this behavior. Dynamic range compressors always have some kind memory across several frames. But even after disabling DRC, the difference was still there. I would really be curious if that's a principal property of AC3 being non-deterministic or if it's a liba52 bug.
Conclusions
The table below lists all audio codecs, which were taken into consideration. They represent a huge percentage of all files found in the wild. The next important codecs are the uncompressed ones, but these are always sample accurate.
| Compression | Library | Overlap | Bit reservoir | Bit exact |
| MPEG-1, layer II | libmad | - | - | + |
| MPEG-1, layer III | libmad | + | + | + |
| AAC | faad2 | + | ? (assumed -) | + |
| AC3 | liba52 | + | ? (assumed -) | - (see image above) |
| Vorbis | libvorbis | + | - | + |
Obtaining the information summarized here was a very painful process with web researches and experiments. The documentation of the decoder libraries regarding sample accurate and bit exact seeking is extremely sparse if not non-existing.
Saturday, May 1, 2010
Processing compressed streams with gmerlin
As I already mentioned, a main goal of this development cycle is to read compressed streams on the input side and write compressed streams on the encoding side. It's a bit of work, but it's definitely worth it because it offers enormous possibilities:
To limit the possibilities of creating broken files, we are a bit strict about the
codecs we support for compressed I/O. This means, that with the new feature you cannot automatically transfer all compressed streams. For compressed I/O the following conditions
must be met:
For transferring compressed packets, we need 2 data structures:
gmerlin-avdecoder
There are 2 new functions for getting the compression format of A/V streams:
If you decided to read compressed packets from a stream, pass
libgmerlin
In the gmerlin library, the new feature shows up mainly in the plugin API. The input plugin (
In the gmerlin transcoder you have a configuration for each A/V stream:
 The options for the stream can be "transcode", "copy (if possible)" or "forget". Copying of a stream is possible if the following conditions are met:
The options for the stream can be "transcode", "copy (if possible)" or "forget". Copying of a stream is possible if the following conditions are met:
If a stream cannot be copied, it will be transcoded.
libquicktime
Another major project was support in libquicktime. It's a bit nasty because libquicktime codecs do tasks, which should actually be done by the (de)multiplexer. In practice this means that compressed streams have to be enabled for each codec and container separately. The public API is in compression.h. It was modeled after the functions in libgmerlin, but the definition of the compression (
I made a small tool
Status and TODO
Most major codecs and containers work, although not all of them are heavily tested. Therefore I cannot guarantee, that files written that way will be compatible with all other decoders. Future work will be testing, fixing and supporting more codecs in more containers. Of course any help (like bugreports or compatibility testing on windows or OSX) is highly appreciated.
With this feature my A/V pipelines are ready for a 1.x version now.
- Lossless transmultiplexing from one container to another
- Adding/removing streams of a file without recompressing the other streams.
- Lossless concatenation of compressed files
- Changing metadata of files (i.e. mp3/vorbis tagging)
- Quicktime has some codecs, which correspond to image formats (png, jpeg, tiff, tga). Supporting compressed frames can convert single images to quicktime movies and back
- In some cases broken files can be fixed as well
To limit the possibilities of creating broken files, we are a bit strict about the
codecs we support for compressed I/O. This means, that with the new feature you cannot automatically transfer all compressed streams. For compressed I/O the following conditions
must be met:
- The precise codec must be known to gavl. While for decoding it never matters if we have MPEG-1 or MPEG-2 video (libmpeg2 decodes both), for compressed I/O it must be known.
- For some codecs, we need other parameters like the bitrate or if the stream contains B-frames or field pictures.
- Each audio packet must consist of an independently decompressable frame and we must know, how many uncompressed samples are contained.
- For each video packet, we must know the pts, how long the frame will be displayed and if it's a keyframe.
For transferring compressed packets, we need 2 data structures:
- An info structure, which describes the compression format (i.e. the codec). The actual codec is an enum (similar to ffmpegs CodecID), but other parameters can be required as well (see above).
- A structure for a data packet.
gavl/compression.h. Gavl itself never messes around with the contents of compressed packets, if just provides some housekeeping functions for packets and compression definitions. The definitions were moved here, because it's the only common dependency of gmerlin and gmerlin-avdecoder and I didn't want to define that twice.gmerlin-avdecoder
There are 2 new functions for getting the compression format of A/V streams:
int bgav_get_audio_compression_info(bgav_t * bgav, int stream,
gavl_compression_info_t * info)
int bgav_get_video_compression_info(bgav_t * bgav, int stream,
gavl_compression_info_t * info)
bgav_select_track(). If the demuxer doesn't meet the above goals for a stream it's tried with a parser. If there is no parser for this stream, compressed output fails and the functions return 0.If you decided to read compressed packets from a stream, pass
BGAV_STREAM_READRAW to bgav_set_audio_stream() or bgav_set_video_stream(). Then you can read compressed packets with:int bgav_read_audio_packet(bgav_t * bgav, int stream, gavl_packet_t * p);
int bgav_read_video_packet(bgav_t * bgav, int stream, gavl_packet_t * p);
bgavdemux, which writes the compressed packets to raw files, but only if the compression supports a raw format. This is e.g. not the case for vorbis or theora.libgmerlin
In the gmerlin library, the new feature shows up mainly in the plugin API. The input plugin (
bg_input_plugin_t) got 4 new functions, which have the identical meaning as their counterparts in gmerlin-avdecoder:int (*get_audio_compression_info)(void * priv, int stream,
gavl_compression_info_t * info);
int (*get_video_compression_info)(void * priv, int stream,
gavl_compression_info_t * info);
int (*read_audio_packet)(void * priv, int stream, gavl_packet_t * p);
int (*read_video_packet)(void * priv, int stream, gavl_packet_t * p);
int (*writes_compressed_audio)(void * priv,
const gavl_audio_format_t * format,
const gavl_compression_info_t * info);
int (*writes_compressed_video)(void * priv,
const gavl_video_format_t * format,
const gavl_compression_info_t * info);
int (*add_audio_stream_compressed)(void * priv, const char * language,
const gavl_audio_format_t * format,
const gavl_compression_info_t * info);
int (*add_video_stream_compressed)(void * priv,
const gavl_video_format_t * format,
const gavl_compression_info_t * info);
int (*write_audio_packet)(void * data, gavl_packet_t * packet, int stream);
int (*write_video_packet)(void * data, gavl_packet_t * packet, int stream);
In the gmerlin transcoder you have a configuration for each A/V stream:
- The source can deliver compressed packets
- The encoder can write compressed packets of that format
- No subtitles are blended onto video images
If a stream cannot be copied, it will be transcoded.
libquicktime
Another major project was support in libquicktime. It's a bit nasty because libquicktime codecs do tasks, which should actually be done by the (de)multiplexer. In practice this means that compressed streams have to be enabled for each codec and container separately. The public API is in compression.h. It was modeled after the functions in libgmerlin, but the definition of the compression (
lqt_compression_info_t) is slightly different because inside libquicktime we can't use gavl.I made a small tool
lqtremux. It can either be called with a single file as an argument, in which case all A/V streams are exported to separate quicktime files. If you pass more than one file on the commandline, the last file is considered the output file and all tracks of all other files are multiplexed into the output file. Note that lqtremux is a pretty dumb application, which was written mainly as a demonstration and testbed for the new functionality. In particular you cannot copy some tracks while transcoding others. For more sophisticated tasks use gmerlin-transcoder or write your own tool.Status and TODO
Most major codecs and containers work, although not all of them are heavily tested. Therefore I cannot guarantee, that files written that way will be compatible with all other decoders. Future work will be testing, fixing and supporting more codecs in more containers. Of course any help (like bugreports or compatibility testing on windows or OSX) is highly appreciated.
With this feature my A/V pipelines are ready for a 1.x version now.
Saturday, March 20, 2010
libtheora vs. libschrödinger vs. x264
Doing a comparison of lossy codecs was always on my TODO list. That's mostly because of the codec-related noise I read (or skip) on mailing lists and propaganda for the royality free codecs with semi-technical arguments but without actual numbers. A while ago I made some quick and dirty PSNR tests, where x264 turned out to be the clear winner. But recently we saw new releases of libtheora and libschrödinger with improved encoding quality, so maybe now is the time to investigate things a bit deeper.
Specification vs implementation
With non-trivial compression techniques (and all techniques I tried are non-trivial) you must make a difference between a specification and an implementation. The specification defines how the compressed bitstream looks like, and suggests how the data can be compressed. I.e. it specifies if motion vectors can be stored with subpixel precision or if B-frames are possible. The implementation does the actual work of compressing the data. It has a large degree of freedom e.g. it lets you choose between several motion estimation methods or techniques for quantization or rate control. If you fully read and understood all specifications, you can make a rough estimation, which specification allows more powerful compression. But if you want numbers, you can only compare implementations.
This implies, that statements like "Dirac is better than H.264" (or vice versa) are inherently idiotic.
Candidates
If compression algorithms are completely different, it's not easy to find comparable codec parameters. Some codecs are very good for VBR encoding but suck when forced to CBR. Some codecs are optimized for low-bitrate, others are work better at higher bitrates. Therefore I decided for very simple test rules:
Some lossless sequences in y4m format can be downloaded from the xiph site. I wanted a file, which has fast global motion as well as slower changing parts. Also the uncompressed size shouldn't be too large to keep the transcoding- and analysis time at a reasonable level. Therefore I decided to use the foreman. Of course for a better estimation you would need much more and longer sequences. Feel free to repeat the experiment with other files and tell about the results.
Analysis tool
I wrote a small tool
Each line consists of:
You can get this tool if you upgrade gavl, gmerlin and gmerlin-avdecoder from CVS. It makes use of a brand new feature (extracting compressed frames), which is needed for the video bitrate calculation (i.e. without the overhead from the container).
Results
See below for the PSNR and MSSIM results for the 3 libraries.


Conclusion
The quality vs. bitrate differences are surprisingly small. While x264 still wins, the royality free versions lag behind by just 2-3 dB of PSNR. Also surprising is that libtheora and libschroedinger are so close together given the fact, that Dirac has e.g. B-frames, while theora has just I- and P-frames. Depending on your point of view, this is good news for libtheora or bad news for libschroedinger
Another question is of course, if this comparison is completely fair. A further project could now be to take the codecs and tweak single parameters to check, how the quality can be improved. Also one might add other criteria like encoding-/decoding speed as well. Making tests with different types of footage would also give more insight.
To summarize that, I don't state that these numbers are the final wisdom. But at least they are numbers, and neither propaganda nor marketing.
Specification vs implementation
With non-trivial compression techniques (and all techniques I tried are non-trivial) you must make a difference between a specification and an implementation. The specification defines how the compressed bitstream looks like, and suggests how the data can be compressed. I.e. it specifies if motion vectors can be stored with subpixel precision or if B-frames are possible. The implementation does the actual work of compressing the data. It has a large degree of freedom e.g. it lets you choose between several motion estimation methods or techniques for quantization or rate control. If you fully read and understood all specifications, you can make a rough estimation, which specification allows more powerful compression. But if you want numbers, you can only compare implementations.
This implies, that statements like "Dirac is better than H.264" (or vice versa) are inherently idiotic.
Candidates
- libschroedinger-1.0.9
- libtheora-1.1.0
- x264 git version from 2010-03-19
If compression algorithms are completely different, it's not easy to find comparable codec parameters. Some codecs are very good for VBR encoding but suck when forced to CBR. Some codecs are optimized for low-bitrate, others are work better at higher bitrates. Therefore I decided for very simple test rules:
- All codec settings are set to their defaults found in the sourcecode of the libraries. This leaves the decision of good parameters to the developers of the libraries. I upgraded the codec parameters in libquicktime and the gmerlin encoding plugins for the newest library versions.
- The only parameter, which is changed, corresponds to the global quality of the compression (all libraries have such a parameter). Multiple files are encoded with different quality settings.
- From the encoded files the average bitrate is calculated and the quality (PSNR and MSSIM) is plotted as a function of the average bitrate.
Some lossless sequences in y4m format can be downloaded from the xiph site. I wanted a file, which has fast global motion as well as slower changing parts. Also the uncompressed size shouldn't be too large to keep the transcoding- and analysis time at a reasonable level. Therefore I decided to use the foreman. Of course for a better estimation you would need much more and longer sequences. Feel free to repeat the experiment with other files and tell about the results.
Analysis tool
I wrote a small tool
gmerlin_vanalyze, which is called with the original and encoded files as only arguments. It will then output something like:0 33385 47.137417 0.992292
1 17713 45.936294 0.989990
2 17693 45.998659 0.990233
3 17361 46.008802 0.990297
4 19253 46.144632 0.990582
5 19005 46.179699 0.990648
....
295 24454 45.174282 0.993100
296 23841 44.653152 0.992318
297 20966 43.848303 0.991013
298 13941 41.996157 0.987494
299 11682 41.852630 0.987321
# Average values
# birate PSNR SSIM
# 4941941.26 46.075177 0.991434
Each line consists of:
- Frame number
- Compressed size of this frame in bytes
- Luminance PSNR in dB of this frame
- Mean SSIM of this frame
You can get this tool if you upgrade gavl, gmerlin and gmerlin-avdecoder from CVS. It makes use of a brand new feature (extracting compressed frames), which is needed for the video bitrate calculation (i.e. without the overhead from the container).
Results
See below for the PSNR and MSSIM results for the 3 libraries.


Conclusion
The quality vs. bitrate differences are surprisingly small. While x264 still wins, the royality free versions lag behind by just 2-3 dB of PSNR. Also surprising is that libtheora and libschroedinger are so close together given the fact, that Dirac has e.g. B-frames, while theora has just I- and P-frames. Depending on your point of view, this is good news for libtheora or bad news for libschroedinger
Another question is of course, if this comparison is completely fair. A further project could now be to take the codecs and tweak single parameters to check, how the quality can be improved. Also one might add other criteria like encoding-/decoding speed as well. Making tests with different types of footage would also give more insight.
To summarize that, I don't state that these numbers are the final wisdom. But at least they are numbers, and neither propaganda nor marketing.
Saturday, February 6, 2010
AVCHD timecode update
After this post I got some infos from a cat, which helped me to understand the AVCHD metadata format much better. This post summarizes, what I currently know.
AVCHD metadata are stored in an SEI message of type 5 (user data unregistered). These messages start with a GUID (indicating the type of the data). The rest is not specified in the H.264 spec. For AVCHD metadata the data structure is as follows:
1. The 16 byte GUID, which consists of the bytes
2. 4 bytes
which are "MDPM" in ASCII.
3. One byte, which specifies the number of tags to follow
4. Each tag begins with one byte specifying the tag type followed by 4 bytes of data.
The date and time are stored in tags
Tag
The 4 bytes in tag
There are more informations stored in this SEI message, check here for a list.
If you want to make further research on this, you can download gmerlin-avdecoder from CVS, open the file
Then you can use
AVCHD metadata are stored in an SEI message of type 5 (user data unregistered). These messages start with a GUID (indicating the type of the data). The rest is not specified in the H.264 spec. For AVCHD metadata the data structure is as follows:
1. The 16 byte GUID, which consists of the bytes
0x17 0xee 0x8c 0x60 0xf8 0x4d 0x11 0xd9 0x8c 0xd6 0x08 0x00 0x20 0x0c 0x9a 0x662. 4 bytes
0x4d 0x44 0x50 0x4dwhich are "MDPM" in ASCII.
3. One byte, which specifies the number of tags to follow
4. Each tag begins with one byte specifying the tag type followed by 4 bytes of data.
The date and time are stored in tags
0x18 and 0x19.Tag
0x18 starts with an unknown byte. I saw values between 0x02 and 0xff in various files. It seems however that it has a constant value for all frames in a file. The 3 remaining bytes are the year and the month in BCD coding (0x20 0x09 0x08 means August 2009).The 4 bytes in tag
0x19 are the day, hour, minute and second (also BCD coded).There are more informations stored in this SEI message, check here for a list.
If you want to make further research on this, you can download gmerlin-avdecoder from CVS, open the file
lib/parse_h264.c and uncomment the following line (at the very beginning):// #define DUMP_AVCHD_SEIThen you can use
bgavdump on your files. It will decode the first 10 frames from the file. If you want to decode e.g. 100 frames, usebgavdump -nf 100 your_file.mts
Wednesday, January 27, 2010
Video quality characterization techniques
When developing video processing algorithms and tuning them for quality, one needs proper measurement facilities, otherwise one will end up doing voodoo. This post introduces two prominent methods for calculating the differences of two images (the "original" and the "reproduced" one) and get a value, which allows to estimate, how well the images coincide.
PSNR
The most prominent method is the PSNR (peaked signal-to-noise ratio). It is based on the idea, that the reproduced image consists of the original plus a "noise signal". The noise level can be characterized by the signal-to-noise ratio and is usually given in dB. Values below 0 dB mean that the noise power is larger than the signal. For identical images (zero noise), the PSNR is infinite.
Advantage is, that it's a well established method and the calculation is extremely simple (see here for the formula). Disadvantage is, that it is a purely mathematical calculation of the noise power, while the human psychovisual system is completely ignored.
Thus, one can easily to make 2 images, which have different types of compression artifacts (i.e. from different codecs) and have the similar PSNR compared to the original. But one looks much better than the other. Therefore, current opinion among specialists is, that PSNR can be used or optimizing one codec, while it fails for comparing different codecs. Unfortunately, many codec comparisons in the internet still use PSNR.
SSIM
SSIM (structural similarity) was fist suggested by Zhou Wang et.al. in the paper "Image Quality Assessment: From Error Visibility to Structural Similarity" (IEEE Transactions on image processing, Vol. 13, No. 4, April 2004, PDF).
The paper is very well written and I recommend anyone, who is interested, to read it. In short: The structural similarity is composed of 3 values:
A difference to PSNR is, that the SSIM index for a pixel is calculated by taking the surrounding pixels into account. It calculates some characteristic numbers known from statistics: The mean value, the standard deviation and correlation coefficient.
One problem with the SSIM is, that the algorithm has some free parameters, which are slightly different in each implementation. Therefore you should be careful when comparing your results with numbers coming from a different routine. I took the parameters from the original paper, i.e. K1 = 0.01, K2 = 0.03 and an 11x11 Gaussian window with a standard deviation of 1.5 pixels.
Implementations
Both methods are available in gavl (SSIM only in CVS for now), but their APIs are slightly different. To calculate the PSNR, use:
For SSIM you can use:
It never matters which image is passed in
Example
Below you see 11 Lena images compressed with libjpeg at quality levels from 0 to 100 along with their PSNR, SSIM and file size:











With these numbers I made a plot, which shows the PSNR and SSIM as a function of the JPEG quality:
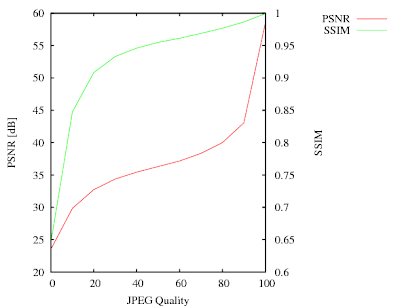 The JPEGs have the most visible differences for qualities between 0 and 40. In this range the SSIM curve has the largest gradient. Above 40 (where the visual quality doesn't change much), the SSIM becomes more or less linear and reaches almost 1 for the best quality.
The JPEGs have the most visible differences for qualities between 0 and 40. In this range the SSIM curve has the largest gradient. Above 40 (where the visual quality doesn't change much), the SSIM becomes more or less linear and reaches almost 1 for the best quality.
The PSNR curve is a bit misleading. It has the steepest gradient for the highest quality. This is understandable because PSNR would become infinite for the lossless (perfect quality) case. It has however not much to do with the subjective impression. PSNR however is better for fine-tuning codecs at very high quality levels. That's because the PSNR values will change more strongly, while SSIM will always be almost one.
Now I have the proper tools to make a comparison of different video codecs.
PSNR
The most prominent method is the PSNR (peaked signal-to-noise ratio). It is based on the idea, that the reproduced image consists of the original plus a "noise signal". The noise level can be characterized by the signal-to-noise ratio and is usually given in dB. Values below 0 dB mean that the noise power is larger than the signal. For identical images (zero noise), the PSNR is infinite.
Advantage is, that it's a well established method and the calculation is extremely simple (see here for the formula). Disadvantage is, that it is a purely mathematical calculation of the noise power, while the human psychovisual system is completely ignored.
Thus, one can easily to make 2 images, which have different types of compression artifacts (i.e. from different codecs) and have the similar PSNR compared to the original. But one looks much better than the other. Therefore, current opinion among specialists is, that PSNR can be used or optimizing one codec, while it fails for comparing different codecs. Unfortunately, many codec comparisons in the internet still use PSNR.
SSIM
SSIM (structural similarity) was fist suggested by Zhou Wang et.al. in the paper "Image Quality Assessment: From Error Visibility to Structural Similarity" (IEEE Transactions on image processing, Vol. 13, No. 4, April 2004, PDF).
The paper is very well written and I recommend anyone, who is interested, to read it. In short: The structural similarity is composed of 3 values:
- Luminance comparison
- Contrast comparison
- Structure comparison
A difference to PSNR is, that the SSIM index for a pixel is calculated by taking the surrounding pixels into account. It calculates some characteristic numbers known from statistics: The mean value, the standard deviation and correlation coefficient.
One problem with the SSIM is, that the algorithm has some free parameters, which are slightly different in each implementation. Therefore you should be careful when comparing your results with numbers coming from a different routine. I took the parameters from the original paper, i.e. K1 = 0.01, K2 = 0.03 and an 11x11 Gaussian window with a standard deviation of 1.5 pixels.
Implementations
Both methods are available in gavl (SSIM only in CVS for now), but their APIs are slightly different. To calculate the PSNR, use:
void gavl_video_frame_psnr(double * psnr,
const gavl_video_frame_t * src1,
const gavl_video_frame_t * src2,
const gavl_video_format_t * format);
src1, src2 and format arguments are obvious. The result (already in dB) is returned in psnr for each component. The order is RGB(A), Y'CbCr(A) or Gray(A) depending on the pixelformat. PSNR can be calculated for all pixelformats, but usually one will use a Y'CbCr format and take only the value for the Y' component. In all my tests the PSNR values for chrominance were much higher, so the luminance PSNR is the most pessimistic (i.e. most honest) value.For SSIM you can use:
int gavl_video_frame_ssim(const gavl_video_frame_t * src1,
const gavl_video_frame_t * src2,
gavl_video_frame_t * dst,
const gavl_video_format_t * format);
src1, src2 and format are the same as for PSNR. The pixelformat however must be GAVL_GRAY_FLOAT, implying that only the luminance is taken into account. This decision was made after the experiences with PSNR. The SSIM indices for each pixel is then returned in dst, which must be created with the same format. The MSSIM (mean SSIM) for the whole image can then be obtained by averaging the SSIM values over all pixels. The function returns 1 if the SSIM could be calculated or 0 if the pixelformat was not GAVL_GRAY_FLOAT or the image is smaller than the 11x11 window.It never matters which image is passed in
src1 and which in src2 because both algorithms are symmetric.Example
Below you see 11 Lena images compressed with libjpeg at quality levels from 0 to 100 along with their PSNR, SSIM and file size:

Quality: 0, PSNR: 23.54 dB, SSIM: 0.6464, Size: 2819 bytes

Quality: 10, PSNR: 29.84 dB, SSIM: 0.8473, Size: 4305 bytes

Quality: 20, PSNR: 32.74 dB, SSIM: 0.9084, Size: 5890 bytes

Quality: 30, PSNR: 34.38 dB, SSIM: 0.9331, Size: 7376 bytes

Quality: 40, PSNR: 35.44 dB, SSIM: 0.9460, Size: 8590 bytes

Quality: 50, PSNR: 36.31 dB, SSIM: 0.9549, Size: 9777 bytes

Quality: 60, PSNR: 37.16 dB, SSIM: 0.9612, Size: 11101 bytes

Quality: 70, PSNR: 38.34 dB, SSIM: 0.9688, Size: 13034 bytes

Quality: 80, PSNR: 40.00 dB, SSIM: 0.9768, Size: 16410 bytes

Quality: 90, PSNR: 43.06 dB, SSIM: 0.9863, Size: 24308 bytes

Quality: 100, PSNR: 58.44 dB, SSIM: 0.9993, Size: 94169 bytes
With these numbers I made a plot, which shows the PSNR and SSIM as a function of the JPEG quality:
 The JPEGs have the most visible differences for qualities between 0 and 40. In this range the SSIM curve has the largest gradient. Above 40 (where the visual quality doesn't change much), the SSIM becomes more or less linear and reaches almost 1 for the best quality.
The JPEGs have the most visible differences for qualities between 0 and 40. In this range the SSIM curve has the largest gradient. Above 40 (where the visual quality doesn't change much), the SSIM becomes more or less linear and reaches almost 1 for the best quality.The PSNR curve is a bit misleading. It has the steepest gradient for the highest quality. This is understandable because PSNR would become infinite for the lossless (perfect quality) case. It has however not much to do with the subjective impression. PSNR however is better for fine-tuning codecs at very high quality levels. That's because the PSNR values will change more strongly, while SSIM will always be almost one.
Now I have the proper tools to make a comparison of different video codecs.
Sunday, January 24, 2010
Disabling the X11 screensaver from a client
One of the most annoying experiences when watching videos with friends on cold winter evenings is, when the screensaver starts. Media players therefore need a way to switch that off by one or several means.
The bad news is, that there is no official method for such a trivial task, which works on all installations. In addition, there is the energy saving mode, which has nothing to do with the screensaver, and must thus be disabled separately.
The Xlib method
You get the screensaver status with
Old gnome method
Older gnome versions had a way to ping the screensaver by executing the command:
Actually pinging the screensaver (which resets the idle timer) is a better method, because it restores the screensaver even if the player got killed (or crashed). The bad news is, that starting with some never gnome version (don't know exactly which), this stopped working. To make things worse, the command is still available and even gives zero return code, it's just a noop.
KDE
I never owned a Linux installation with KDE. But with a little help from a friends, I found a method. My implementation however is so ugly, that I won't show it here :)
The holy grail: Fake key events
After the old gnome variant stopped working for me, I finally found the XTest extension. It was developed to test XServers. I abuse it to send fake key events, which are handled indentically to real keystrokes. They will reset the idle counters of all screensaver variants, and will also disable the energy saving mode.
Also it's a ping approach (with the advantage described above). But it works with an X11 protocol request instead of forking a subprocess, so the overhead will be much smaller. The documentation for the XTest extension is from 1992, so I expect it to be present on all installations, which are sufficiently new for video playback.
Here is how I implemented it:
1. Include
2. Test for presence of the XTest extension with
3. Get the keycode of the left shift key with
4. Each 40 seconds, I press the key with
5. One video frame later, I release the key with
The one frame delay was done to make sure, that the press and release events will arrive with different timestamps. I don't want to know, what happens if press- and release-events for a key have identical timestamps.
This method will hopefully work forever, no matter what crazy ideas the desktop developers get in the future. Also, this is one more reason not to use any GUI toolkit for video playback. If you use Xlib and it's extensions, you have full access to all available features of X. When using a toolkit, you have just the features the toolkit developers think you deserve.
The bad news is, that there is no official method for such a trivial task, which works on all installations. In addition, there is the energy saving mode, which has nothing to do with the screensaver, and must thus be disabled separately.
The Xlib method
You get the screensaver status with
XGetScreenSaver(), disable it with XSetScreenSaver() and restore it after video playback. Advantage is, that this method is core X11. Disadvatage is, that it never works.Old gnome method
Older gnome versions had a way to ping the screensaver by executing the command:
gnome-screensaver-command --poke > /dev/null 2> /dev/nullActually pinging the screensaver (which resets the idle timer) is a better method, because it restores the screensaver even if the player got killed (or crashed). The bad news is, that starting with some never gnome version (don't know exactly which), this stopped working. To make things worse, the command is still available and even gives zero return code, it's just a noop.
KDE
I never owned a Linux installation with KDE. But with a little help from a friends, I found a method. My implementation however is so ugly, that I won't show it here :)
The holy grail: Fake key events
After the old gnome variant stopped working for me, I finally found the XTest extension. It was developed to test XServers. I abuse it to send fake key events, which are handled indentically to real keystrokes. They will reset the idle counters of all screensaver variants, and will also disable the energy saving mode.
Also it's a ping approach (with the advantage described above). But it works with an X11 protocol request instead of forking a subprocess, so the overhead will be much smaller. The documentation for the XTest extension is from 1992, so I expect it to be present on all installations, which are sufficiently new for video playback.
Here is how I implemented it:
1. Include
<X11/extensions/XTest.h>, link with -lXtst.2. Test for presence of the XTest extension with
XTestQueryExtension()3. Get the keycode of the left shift key with
XKeysymToKeycode()4. Each 40 seconds, I press the key with
XTestFakeKeyEvent(dpy, keycode, True, CurrentTime);5. One video frame later, I release the key with
XTestFakeKeyEvent(dpy, keycode, False, CurrentTime);The one frame delay was done to make sure, that the press and release events will arrive with different timestamps. I don't want to know, what happens if press- and release-events for a key have identical timestamps.
This method will hopefully work forever, no matter what crazy ideas the desktop developers get in the future. Also, this is one more reason not to use any GUI toolkit for video playback. If you use Xlib and it's extensions, you have full access to all available features of X. When using a toolkit, you have just the features the toolkit developers think you deserve.
Tuesday, January 19, 2010
Gmerlin release on the horizon
New gmerlin prereleases are here:
http://gmerlin.sourceforge.net/gmerlin-dependencies-20100119.tar.bz2
http://gmerlin.sourceforge.net/gmerlin-all-in-one-20100119.tar.bz2
Changes since the last public release are:
Please test it as much as you can and sent problem reports to the gmerlin-general list.
http://gmerlin.sourceforge.net/gmerlin-dependencies-20100119.tar.bz2
http://gmerlin.sourceforge.net/gmerlin-all-in-one-20100119.tar.bz2
Changes since the last public release are:
- Great player simplification. Most changes are internal, but the user should notice much faster seeking. Also the GUI player now updates the video window while the seek-slider is moved.
- Simplification of the plugin configuration: In many places, where we had an extra dialog for configuring plugins, it was merged with the rest of the configuration.
- A new recorder application which records audio (with OSS, Pulseaudio, Alsa, Jack and ESound) and video (with V4L1, V4L2 or the new X11 grabber). Output can be written into files or broadcasted.
- A new encoding frontend (used by the recorder and transcoder), which allows more consistant and unified configuration of encoding setups.
- The video window of the GUI player has now a gmerlin icon and is grouped together with the other windows.
- Like always: Tons of fixes, optimizations and smaller cleanups in all packages. Got another 18% speedup when building AVCHD indexes for example.
- Support for compressed A/V frames in the architecture. This should allow lossless transmultiplexing with the transcoder.
- Support for configuration presets: This will make using gmerlin applications much easier. The presets can be shared among application, i.e. once you found a good encoding preset, you can use it both in the transcoder and the recorder.
Please test it as much as you can and sent problem reports to the gmerlin-general list.
Subscribe to:
Posts (Atom)


